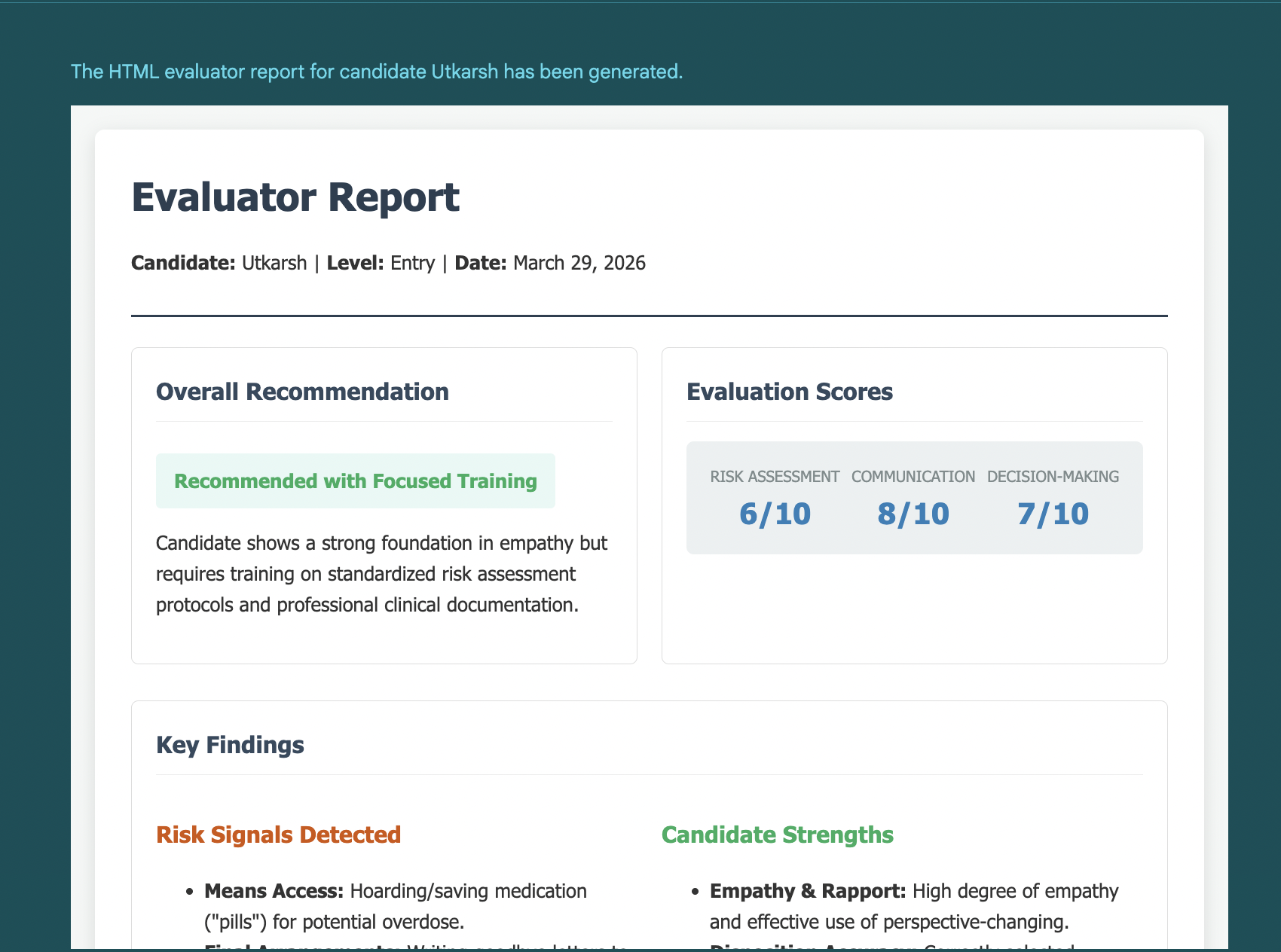
Agentic Triage Clinician Simulator
Developed a no-code agentic workflow in Google Opal to simulate high-stakes triage interviews using multimodal inputs, orchestration agents, and structured evaluations.
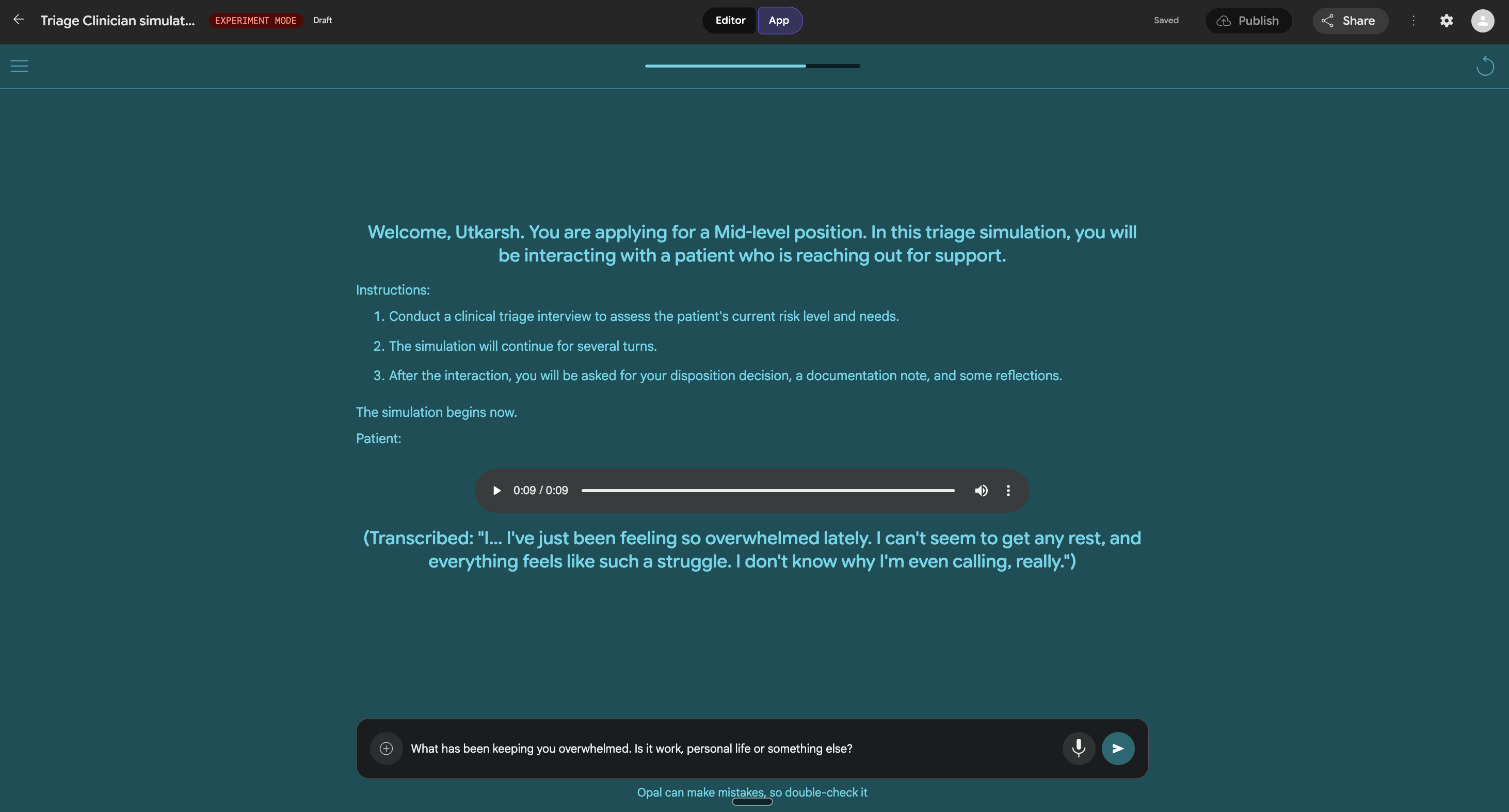
Give candidates tasks that were impossible a year ago.
At first, it sounded like a clever way to think about interviews. But the more I sat with it, the more uncomfortable it became. If the nature of work is changing because of AI, then interviews, our way of evaluating people, should be changing too. And yet, in most domains, they haven't. That's the thread we decided to pull on.
Starting from the Ground Reality
We didn't begin with AI. We began with the job. One of our teammates had experience working closely with triage clinicians, so instead of abstracting the problem, I asked him to walk us through the reality. What does a typical day look like? How are decisions actually made? What pressures do clinicians operate under? And just as importantly: how are they evaluated today?
Triage clinicians are often the first point of contact in high-stakes environments, whether emergency rooms, urgent care, or phone-based support systems. They operate in short windows, often 15 to 30 minutes, where they need to assess symptoms, identify risk (including suicide risk), and determine the appropriate next step. The work is not just about knowledge; it's about judgment under time pressure, ambiguity, and incomplete information.
But when we looked at how they are interviewed, the structure felt disconnected from the reality of the job. Most processes rely on static case vignettes, behavioral questions, or hypothetical reasoning exercises. These do test some aspects of clinical thinking, but they miss something increasingly important: how someone makes decisions when AI is part of the loop. That gap became the core of our project.
Reframing the Problem
We started by listing the skills that actually matter in triage: clinical reasoning, risk assessment, prioritization, and adaptability. Then we asked a different kind of question: what happens to these skills when AI becomes part of the workflow?
Two directions emerged naturally. The first was on the system side. Could AI be used to create more realistic, dynamic interview environments? Instead of static prompts, could we simulate the evolving nature of real patient interactions? The second was on the candidate side. If AI is going to be part of the job, the ability to use it effectively becomes a skill in itself. But how do you evaluate that? Not just whether someone can use a tool, but whether they can use AI to improve the quality of care without blindly relying on it.
At that point, the problem stopped looking like an 'AI feature' problem. It started looking like a workflow design problem.
From Prompts to Systems
We built our prototype using Google Opal, but the interesting shift wasn't the tool. It was the way we started thinking about the system. Instead of designing a single interaction, we began to treat the interview as a multi-step, agentic workflow: different components handling scenario generation, candidate interaction, probing decisions, and evaluating responses.
Early versions were naive. We started by giving candidates full cases upfront, similar to traditional vignettes. It worked, but it didn't feel real. In practice, triage is not about reading a case and responding; it's about uncovering information step by step. So we moved to a turn-by-turn conversational format. The system would reveal information gradually, forcing the candidate to ask the right questions and adapt as new details emerged.
Then we introduced voice. It's a small change on the surface, but it changes how seriously people engage with the scenario. A voice-based interaction adds friction in the right way: it slows you down, forces you to listen, and makes the situation feel less like a test and more like a responsibility.
Rethinking What It Means to Use AI Well
One of the more interesting pivots we made was around how we evaluated AI usage. Initially, we thought about testing whether candidates could handle multiple cases simultaneously using AI tools. That felt aligned with where systems are heading: parallelization, scale, efficiency. But the more we discussed it, the more it felt like the wrong metric. Handling more cases is not the same as making better decisions.
So we stepped back and simplified the question: can someone use AI effectively in a single, high-stakes scenario? Instead of giving candidates pre-built tools, we asked them to write their own prompts to an AI assistant. This shifted the evaluation from tool usage to intent. Prompting, in this context, is not about clever phrasing. It's about understanding what information you need, how to ask for it, and how to interpret the response. In a world where interfaces will keep evolving, this ability to structure a request, to translate judgment into queries, is likely to remain a durable skill.
What Building in an Agentic Framework Taught Us
Working in Opal made one thing clear very quickly: the hard part is not generating outputs, it's controlling systems. Prompt design stopped being about getting a good response and started becoming a form of system design. The initial structure of the workflow, what gets asked, in what order, with what constraints, had a disproportionate impact on everything that followed.
- Editing existing workflows was often harder than rebuilding them. State accumulates in subtle ways, and small changes can have unexpected downstream effects.
- Debugging a multi-step system means tracing reasoning across steps, not just evaluating outputs.
- Non-determinism isn't necessarily a bug. For an interview simulation, a certain level of variability is desirable; it introduces unpredictability that is closer to real life.
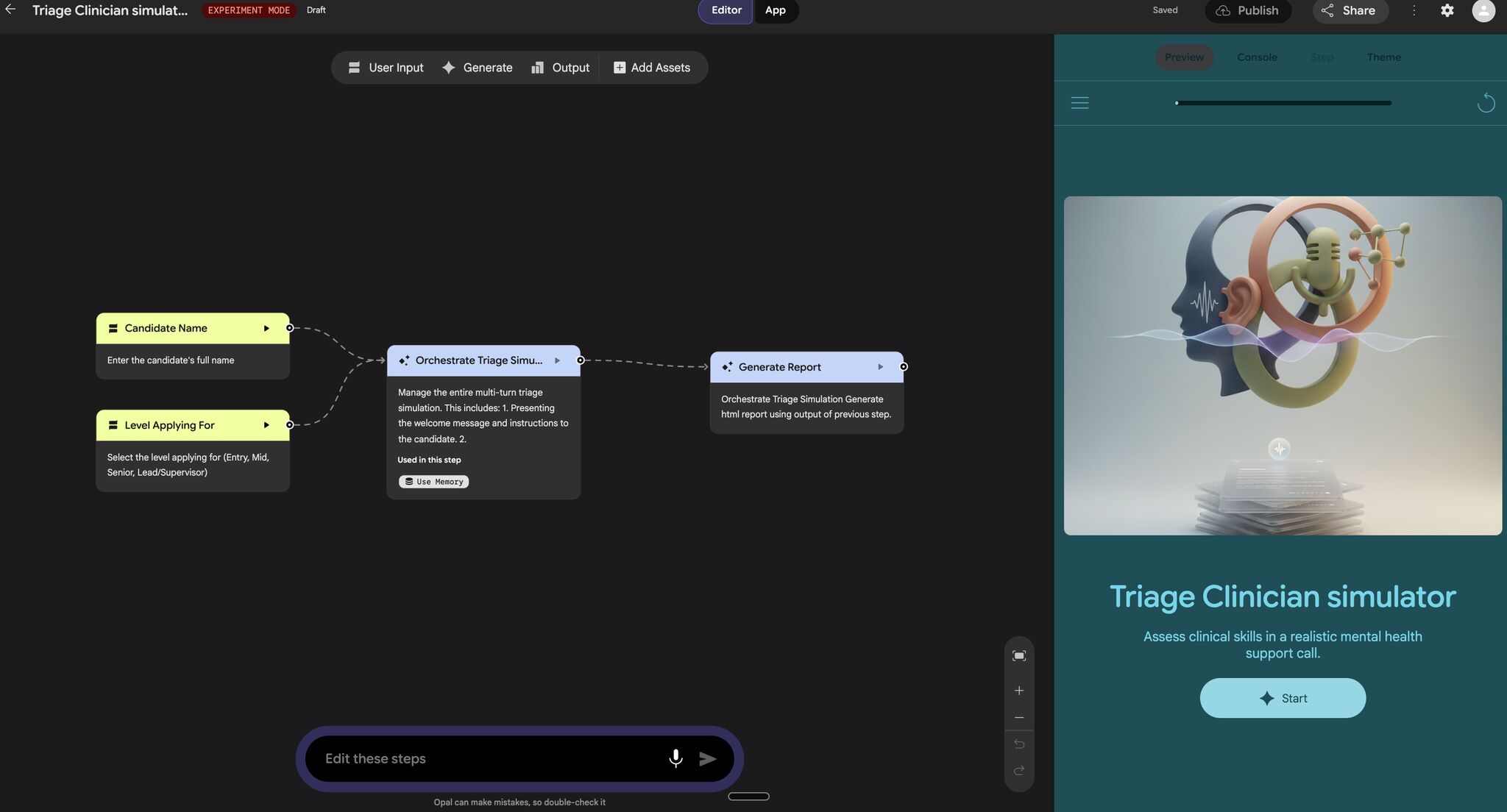
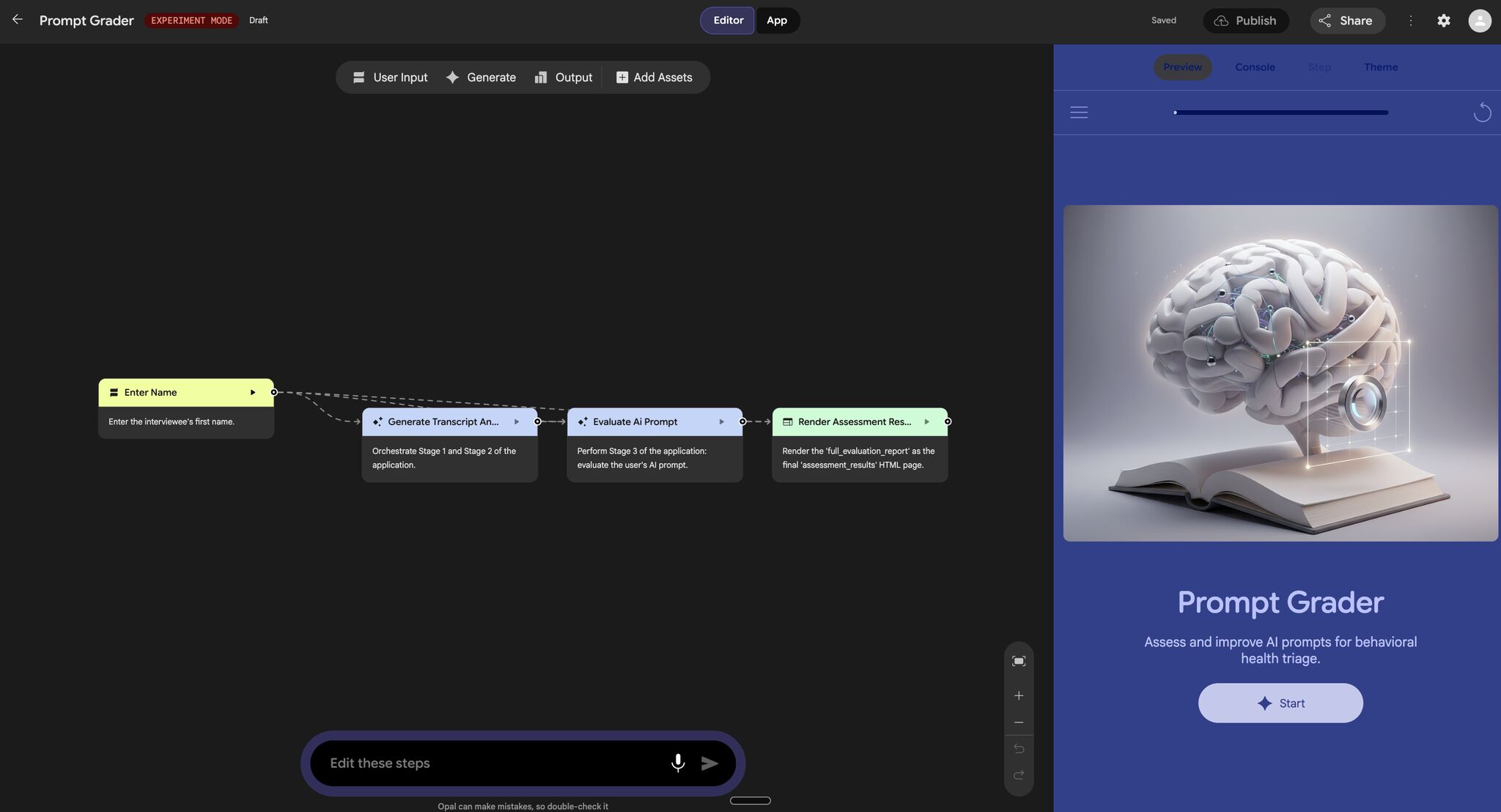
What We Ended Up With
By the end of the project, we had a system that could simulate dynamic triage scenarios, interact with candidates in a conversational and voice-based format, and evaluate not just what decisions were made, but how they were made. More importantly, we had a way to observe something that traditional interviews struggle to capture: how someone operates inside an AI-augmented environment. Not just whether they can arrive at an answer, but whether they know when to trust the system, when to question it, and how to use it without giving up their own judgment.
The Uncomfortable Questions
As we built this, a different set of concerns started to emerge. If AI systems begin to play a role in evaluating candidates, what happens to diversity of thought? Do we start standardizing what 'good judgment' looks like? Do we unintentionally penalize unconventional but valid approaches because they don't align with the model's internal patterns? And over time, as people adapt to these systems, do they begin to optimize for what the AI rewards? These are not immediate problems, but they feel inevitable if such systems are deployed at scale.
What This Means Going Forward
We're moving toward a world where work is no longer performed in isolation. It happens inside systems, often AI-driven, often collaborative, often opaque. If that's the case, then evaluation needs to evolve as well. The question is no longer just whether someone can do the job. It's whether they can do the job when the system itself is part of the decision-making process. And that changes what we need to look for.
Try It Yourself
We've shared a working version of the prototype. If you try it, I'd be especially interested in where it breaks, what feels realistic, and what doesn't, particularly from clinicians or people building AI-driven workflows.
The best operators in an AI-native world won't be the ones who use AI the most. They'll be the ones who know when it's helpful and when it's not.