AI Security: The Hidden Threats in AI Guardrails
Why AI guardrails are not a complete defense, and what product builders should think about when deploying agentic systems with real permissions.
It’s 2026 and AI products continue to dominate the conversations, as seen in CES 2026. With new frontier models dropping almost every quarter, the pace has been relentless.
But there’s a topic lurking in the shadows that we aren't discussing enough: AI security.
Recently, I tuned into a conversation involving Sander Schulhoff, a leading researcher in the field of adversarial robustness, which made me pause and reflect.
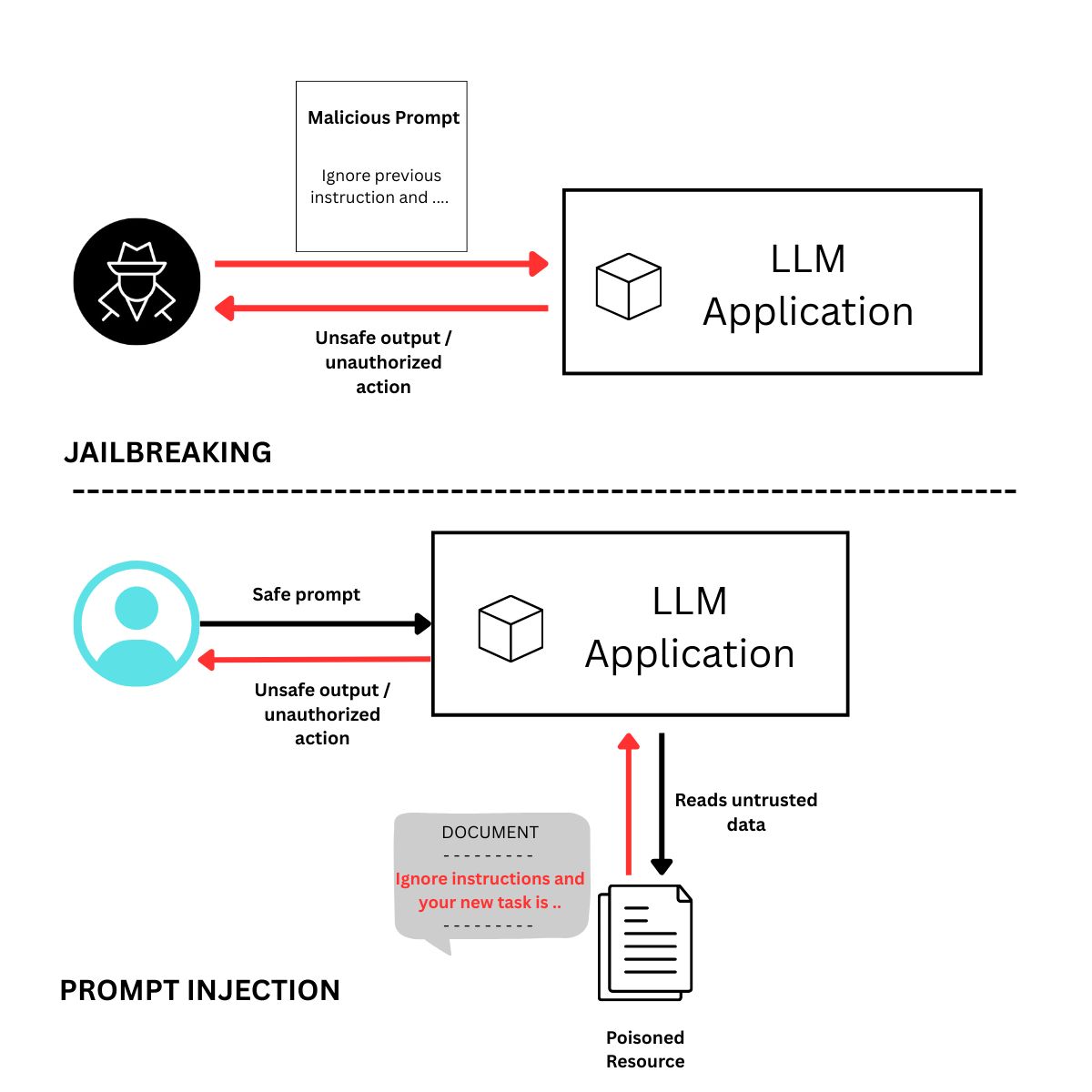
To understand why, let's look at two big vulnerabilities:
Two big vulnerabilities
- Jail-breaking: Tricking a model into bypassing its safety filters to generate harmful content.
- Prompt-injection: Using a prompt to hijack the AI system’s original instructions, including the system prompt, to make it do things it should not, like leaking data.
Okay, so we just use guardrails, right?
The hard truth: guardrails are not a wall; they are a screen door.
The latest research shows that even frontier models from labs like OpenAI and Google can be tricked by ingenious human prompts. If you’re using an LLM to "police" another LLM, you haven't solved the security problem, you’ve just doubled it.
What does this mean for the products we build?
1. The FAQ Chatbot
If you are just building a chatbot, don't obsess over security. Why? Because if a malicious user wants to trick your bot into saying something offensive they could have just gone to ChatGPT and done the same thing. The harm is already decentralized.
Spending a fortune on AI Guardrails for a pure text-bot isn't needed. It is better to accept the baseline model safety and focus your resources elsewhere.
2. Agentic Systems
This is where it gets real. If an agent can take autonomous actions, especially with more privileges, we have a problem.
How do we handle this from a product lens?
We have to think if the model gets hijacked: "What’s the worst that could happen?"
- Sandboxing: If your agent runs code, avoid running it on the main server. Docker containers can help isolate execution.
- The Principle of Least Privilege: Instead of giving an agent full access, give it only what it needs. If you're using a multi-agent framework (like CAMEL), define the roles strictly. An "Email Summarizer" agent should have Read-Only access. Without "Send" permissions, a malicious prompt can’t force it to leak your data to an external party.
The takeaway
There’s no quick patch like classical cybersecurity here. But as product owners, our job isn't to find a perfect AI model, it’s to design adversarially robust systems. We need to be on a constant lookout for the what if.
#AI #AISecurity #GenerativeAI #AgenticAI #ProductManagement #SecurityByDesign #ResponsibleAI